What indexes are and how they are organized internally is very much a 101 topic. For those unfamiliar I can recommend Brent Ozars free class “How to Think Like the SQL Server Engine“. This free video training should be among your first stops on your journey to understanding MSSQL. Microsoft has also published an index design guide that is definitely worth a read.
That being said, here are some of the 101 basics that needs considering when dealing with rowstore indexes.
What is a rowstore index
A rowstore index is data organized as a B-tree where the data is stored on the leaves. This enables the engine to traverse the B-tree to effectively locate the data it is looking for based on the predicates and conditions provided.
Regarding clustered indexes
A clustered index is the table itself. A clustered index is the logical sequence of the pages of a table stored on disk. This also means that there can be only one clustered index on a table as there can be only one logical sort order of the stored table. The index key can be any column(s) in the table, it does not need to be the primary key (even though it often is) and it does not need to be unique (although it is usually recommended). If the clustering keys are not the primary key, adding a primary key will create a non-clustered index on the column(s) included in the primary key to enforce the constraint and enable the index seek operation. For non-unique clustered key duplicates MSSQL adds an integer behind the scenes called a uniqueifier, as each row must be unique to the engine. To maintain the sorted order, clustered indexes use page splits to enforce the logical order of the pages. A typical clustered index is created either by specifying the primary key during table creation or by applying the primary key constraint on an existing heap. An example of applying the PK as a clustered index during table creation is shown here:
--create the table as a clustered index with a primary key
create table t2 (
c1 int,
c2 nvarchar(400),
c3 int,
constraint PK_c1 primary key clustered(c1));
GO
--insert som values just because
insert into t2 values (1,'First row',999),(2,'Second row',888),(3,'Third row',777);
GO
The resulting clustered index with a primary key looks like this in SSMS:
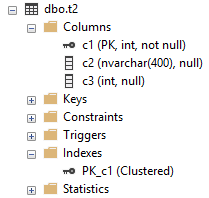
Note that the primary key (PK) is indicated on the column(s) where it resides and that it shows up as a clustered primary key index.
It is possible to have a clustered index (materialized structure) without a primary key (logical structure/constraint). To see why this must be the case we can look at the primary key definition, which states that a primary key must be unique and not null. If the clustered index key can be non-unique this violates the possibility of it being a primary key in these cases. A simple test illustrates this:
--create a table
create table t1 (
c1 int,
c2 nvarchar(400),
c3 int);
GO
--insert som values
with duplicate index keys
insert into t1 values (1,'First row',999),(1,'Second row',888),(2,'Third row',777);
GO
--create clustered index on non-unique column
create clustered index CIX_t1 on t1 (c1);
The resulting clustered index will look like this in SSMS:
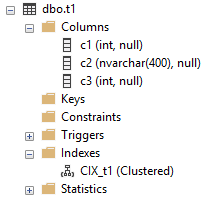
Note that this table does not have a primary key column, which would be indicated by a PK icon and label on the column.
Regarding non-clustered indexes
Non-clustered indexes are a copy of the table, or more precisely a copy of the columns in the table that you specify, hopefully narrower than the table itself. The order of the columns matter when you specify the index as it will control the sort order of the index and hence how the engine can seek into it. A row identifying key called the row locator, that must be unique for each row in the table, is always included in the non-clustered index per default, but it is not sorted by it unless specified. The row locator is either a RID for a heap or the sorting key(s) of the clustered index (including the uniqueifier if the clustering key(s) are non-unique) To be clear, the non-clustered index is linked to the key(s) of the clustered index. It does not matter if this is the tables primary key or not. The concept of the primary key, which is a logical constraint, is to provide a unique reference to the table rows external to the table itself, for instance in a Primary Key / Foreign Key relationship (also known as parent/child).
When working with indexes it can be helpful to visualize how the index will look to see if it will turn out the way you expect. This can be achieved by querying your clustered index or heap. For instance, visualizing how a plain vanilla non-clustered index is stored ( i.e. “create non-clustered index NCI_MYINDEX on t1 (c1, c2, c3)”) can be done by using something similar to the following query: “select c1, c2, c3 from t1 order by c1, c2, c3”. Any incudes are just appended on the end and not sorted. An example from the stack overflow database to illustrate:
--Creating the index
create index IX_userid_score on Comments(UserId, score);
--IX_userid_score looks like
select UserId, Score from comments
order by UserId, Score;
The result set is sorted like the index as illustrated below, first by UserId then by Score:
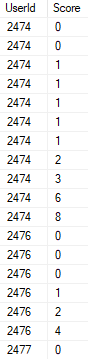
A word of caution: before adding additional non-clustered indexes make sure you understand what problem you are solving and exactly how the index will help address the issue. To put it another way; try to evaluate the index in the context of the problem it is meant to solve.
Regarding Heaps
A table without a clustered index is called a heap. MSSQL will assign a RID (Row ID) behind the scenes to attach to the non-clustered indexes of a heap (in the absence of a clustering key). This enables RID lookup instead of a key lookup (also known as bookmark lookup). Since there is no sorting, there is no need for page splits to uphold the logical order. Instead, because there are no page splits, a row that is updated with a value making it too large to fit on the page will now give rise to what is known as a forwarding record. A forwarding record is a pointer to the page where the data was moved to. Heaps tend to shine for insert intensive workloads, with few updates and deletes.
Heaps also have special considerations to de-allocate pages if they become empty (due to deletes), the most notable is that a table lock is required. If RCSI is activated this becomes even more of an issue.