Fair warning, this post is a little on the long side but bear with me, understanding the differences here is important. All SQL statements used in this post is in a copy friendly version at the bottom.
Concurrency control describes the way a database management system handles simultaneous transactions by controlling the lock and row versioning behavior. MSSQL handles this by letting you choose an isolation level for your transactions through the SET TRANSACTION ISOLATION LEVEL statement.
The isolation levels in MSSQL lets you control how your queries can read data, that is how they will respect other transactions’ locks and how they will handle their shared locks during the transaction. A short and oversimplified explanation of two lock types are needed before continuing:
- a shared lock will block any alteration or deletion of the data being locked but it can be read by anyone. In short it blocks writers but not readers. Shared locks are typically held by SELECT statements.
- an exclusive lock will prevent all alteration and all reads, so it will block writers and readers. Typically, any alteration of data (INSERT, UPDATE or DELETE) will require some sort of exclusive lock.
A definition of a phenomenon called phantom reads is also in order. For the purposes of this post a phantom read can be defined as follows: A phantom read occurs when to identical SELECT statements within the same transaction have deviating result sets.
Read Uncommitted
The least restrictive isolation level in MSSQL is the Read Uncommitted isolation level that reduces blocking by allowing so called “dirty reads”, which means that queries can read uncommitted statements. Additionally, there are no shared locks issued by the read statement which means that all rows being read throughout the statement runtime and transaction runtime is open to change.
The big drawback here is that the data you read can be modified, deleted or added while you read the data, so the result set is not true to/consistent with the data in your database throughout the transaction. Rows can be missing, additional rows can appear and values can have been modified during statement and transaction execution. The typical example is that one might see the same row twice, but with some modified value moving it in the sorted index order or not see a row at all for the same reason. In short: writers will not block readers, readers will not block… anyone period but writers will block writers. The readers will not get trustworthy data in their result set.
The behavior can be illustrated by using the following query:

By running part 1a of the query above there is an open transaction with exclusive locks on the two rows inserted into t1 inside the transaction as seen here (get whatsuplocks here, by Erik Darling).
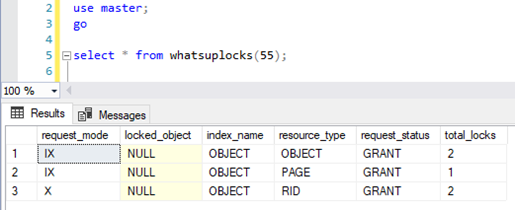
Running part 1b of the following select statement will give us a transaction with a select on t1 in read uncommitted isolation level:
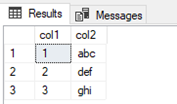
The result set clearly shows that we are reading the existing row and the locked (uncommitted) rows from the uncommitted initial transaction:
Now, running part 2a from the initial transaction will effectively delete a row inside the transaction by rolling back the second insert, insert a new row and then update the first row while still keeping the transaction open. Running part 2b of the second transaction at this point yields the following result set:
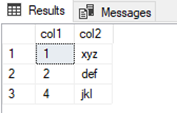
This shows that there are dirty reads and phantom reads with read uncommitted isolation level.
Read Committed (with RCSI off)
Read committed isolation level is the default isolation level in MSSQL and means that there will be no dirty reads, however it is open to non-repeatable reads and phantom reads. Shared locks are released on a least unit read basis at the end of each statement execution (not end of transaction). This means that shared table locks are released at the end of the statement execution while shared page locks are released when the page has been read (i.e. when the next page is processed) and shared row locks are released when the row has been read (i.e. when the next row is processed).
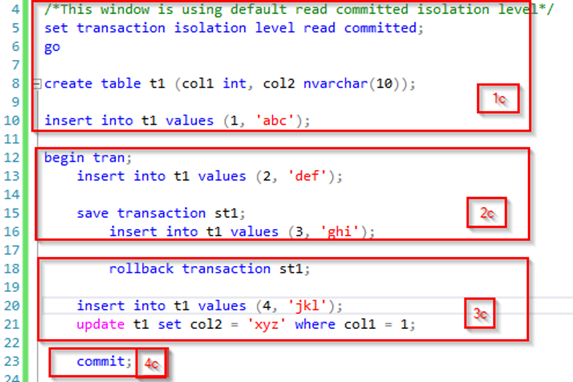
For the read committed isolation level, we can reuse the initial transaction as is, but we will change how we split it up to be able to show the behavior correctly. We will also change the isolation level in our second transaction. This gives us the following queries:
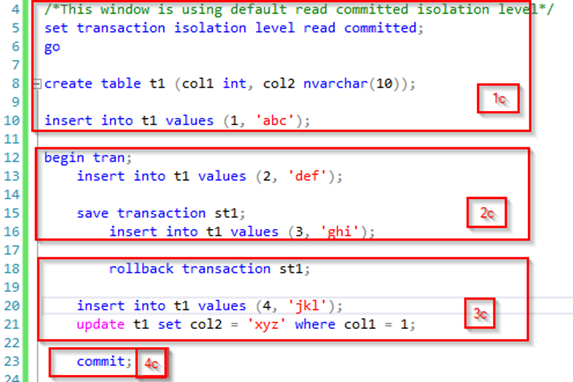
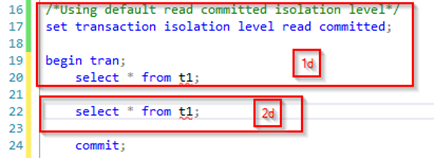
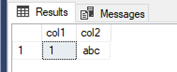
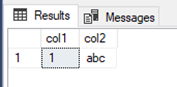
After running part 1c of our initial query, we have a table with a row but no active transaction. If we then kick off the second query (part 1d) it will read this data just fine and get the expected result set:
When part 2c of our initial transaction executes this will take out locks just as before and leave an open transaction with an exclusive lock on the two new rows in the table. When part 2d of our second transaction then executes the locks are honored (no dirty reads), and it is blocked.

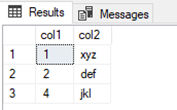
Even after execution of part 1c in the initial query we are still blocked as the transaction has not completed. Running part 4c will finally commit the transaction releasing the locks and allowing part 2d of our second transaction to complete with the following result set:
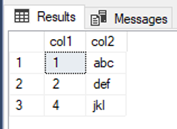
Note that this is not the same result set as the previous identical read statement. This means there still was phantom reads, but we did not have dirty reads as the exclusive locks where honored and the query was blocked instead. Also note that we did not read xyz for col2 in row 1, this is because it was read before hitting the lock on row 2 hence not reread after the UPDATE statement. If 3c and 4c are executed before 2d the result set looks like this:
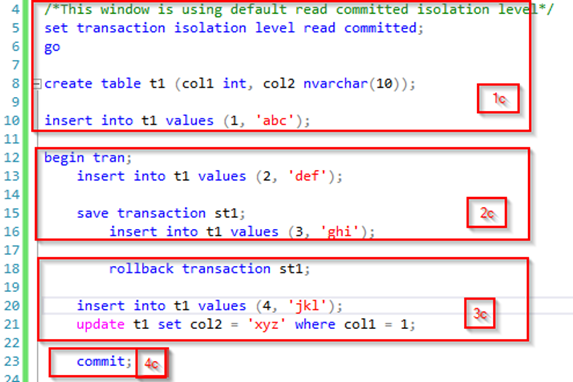
Repeatable Read
The repeatable read isolation level is almost as “strong” as the serializable isolation level (that will be covered in a bit). It does not allow dirty reads and it will not release its shared locks on data it has already read before the transaction ends. That means that already read data will not be altered before the end of the transaction. However, it does allow for phantom reads as insertion of new data that fits the result set is still possible. Our initial query is unchanged, but our second transaction now has another isolation level:
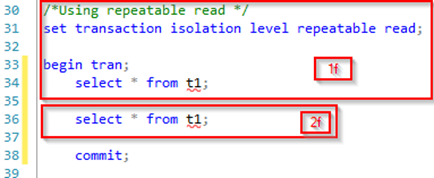
By using the same initial transaction as we did for read uncommitted isolation level the same result set is present after running part 1c followed by 1f of our second transaction:
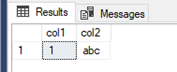
Now, remember that row 1 in t1 has now been read, the locks held by our second query looks like this:
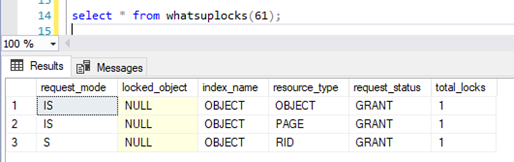
This shows that there is a shared lock on 1 row by our second query, and since there is only one row in the table t1, that row is now locked in a shared lock. This means any writers should be blocked by this lock. This lock will be held to the end of the transaction in the second query. Running part 2c of the initial query starts the transaction placing the expected locks as two rows are inserted:
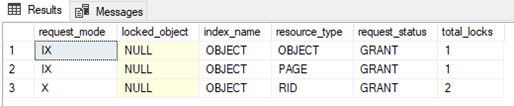
Trying to run part 2d of our second query will cause another locking situation since we do not allow dirty reads (due to circumstances I got new spids):

When we try to run part 3c of our initial transaction we are effectively in a deadlock due to the update statement in query 1 that is blocked by the shared lock on row 1 of t1 and the second query is blocked by the inserts in t1 from our first query. The second transaction was chosen as the deadlock victim, and it will always be this transaction in this scenario as it only contains selects and therefore is easiest to roll back.

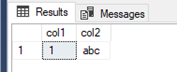
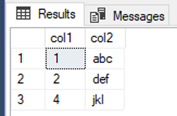
There are no phantom reads in this case, but one of our transactions failed. So, is no result better than a wrong result? It depends, it always will. If this had gone down slightly differently, for instance if the update statement in 3c was skipped both queries would have succeeded when the first transaction committed with the first select returning the same result and the second returning a different result, hence resulting in phantom reads:
First select:
Second select:
Serializable
The most stringent isolation level in MSSQL is the serializable isolation level. It has no dirty reads and requires that no read data can be changed while at the same time enforcing range locks prohibiting new rows to be inserted in the read range of the query for the duration of the transaction. This ensures that all read queries can be executed within the transaction multiple times and return identical result sets. The drawback being that there will be a lot of locking, which usually turns into a lot of blocking. Using the same initial query and modifying the second query to use the serializable isolation level executing 1c followed by part 1g below gives the same expected result set as previously:
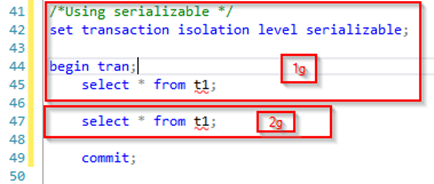
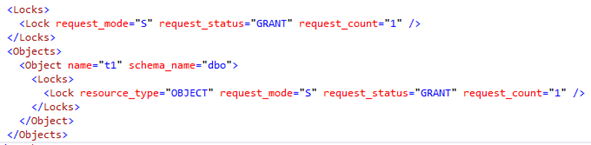
Having a look at the locks taken by our read query it is apparent that the lock is on the table level:
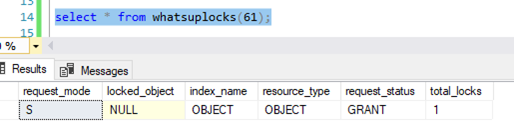
From the lock XML (obtained through sp_WhoIsActive) we can see the details a little more clearly:
Continuing with part 2c of our initial query it is immediately blocked by the shared table lock. Hence, executing part 2g of our second query will give the same result set as previously effectively eliminating phantom reads.
When committing our second transaction the shared lock on t1 is released letting our initial query continue. Note that there was no deadlock this time.
Snapshot
The snapshot isolation level ensures all reads read a transactionally consistent version of the data from the time that the transaction starts (or more accurately when the transaction first accesses data). This means that there will be no dirty reads and no phantom data, but if the dataset being read is changed after the transaction started this change will not be recognized by the query and a transactionally consistent version from the time the transaction started is read instead. This is a way to ensure that even though there are no dirty reads, the reading query will not be blocked by exclusive locks and the reading query does not issue any shared locks as it does not need to. If any data is altered, the query will simply read the transactionally consistent data from the version store. Note that to be able to use this isolation level, the setting “Allow Snapshot Isolation” must be set to True (can be done through GUI or by executing “alter database <db name> set allow_snapshot_isolation on;”).
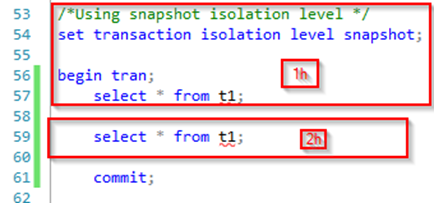
Starting as usual by executing 1c then 1h we get the expected result set:
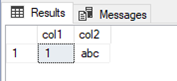
In sys.dm_tran_active_snapshot_database_transactions we can now see our active snapshot transaction, but there is still no data in sys.dm_tran_version_store. This will be populated when the update statement in 3c is executed.

Executing part 2c and 3c and then 2h still gives the same result set, and if we now look at the active snapshot transactions both queries are listed and it shows that the snapshot isolated query has read a version chain:
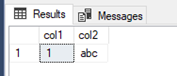

In sys.dm_tran_version_store there is now data, the snapshot, that is read by our read transaction:

Committing the transactions will immediately remove them from the sys.dm_tran_active_snapshot_database_transactions view, however the snapshot data might linger a bit in sys.dm_tran_version_store before being removed.
Read Committed Snapshot Isolation (RCSI)
This is a database setting that effectively will turn on the version store for the entire database effectively turning on snapshot isolation level behavior for all read committed isolation level queries database wide. Since the version store is used the transactional consistency will be from the point in time when the transaction started/first accessed data. To turn this on issue the following command
alter database <db_name> set read_committed_snapshot on;
go
Using RCSI is in many ways a “magic button” to reduce locking and blocking database wide, but be aware that many applications have business logic that relies on locking and blocking. If your application was not developed with RCSI in mind, extensive testing might be needed to ensure expected behavior.
The code
As promised, a copy friendly version of the T-SQL used in this post (for sp_whoisactive and whatsuplocks please visit the appropriate websites)
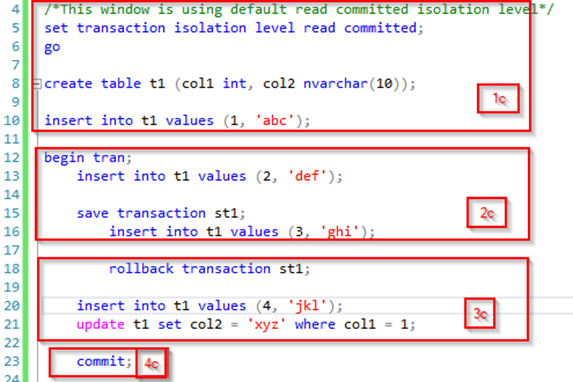
set transaction isolation level read committed;
go
create table t1 (col1 int, col2 nvarchar(10));
insert into t1 values (1, 'abc');
begin tran;
insert into t1 values (2, 'def');
save transaction st1;
insert into t1 values (3, 'ghi');
rollback transaction st1;
insert into t1 values (4, 'jkl');
update t1 set col2 = 'xyz' where col1 = 1;
commit;
drop table t1;
-------------------------------------------------------------
-- set transaction isolation level read uncommitted;
-- set transaction isolation level read committed;
-- set transaction isolation level repeatable read;
-- set transaction isolation level serializable;
-- set transaction isolation level snapshot;
go
begin tran;
select * from t1;
select * from t1;
commit;
------------------------------------------------------------
select * from sys.dm_tran_version_store;
select * from sys.dm_tran_active_snapshot_database_transactions;